Resumen
Proyecto de ciencia de datos para predecir ataques cardíacos mediante análisis exploratorio y multivariante de datos clínicos. Desarrollado como trabajo final del postgrado en la Universidad de Barcelona en Ciencia de Datos aplicado a Medicina y Biología.
El Problema
La predicción temprana de riesgo cardiovascular representa un desafío analítico complejo que requiere la identificación de patrones sutiles en múltiples variables clínicas. Este proyecto busca demostrar cómo las técnicas de ciencia de datos pueden aplicarse al análisis de factores de riesgo cardíaco, proporcionando una herramienta educativa para comprender mejor las relaciones entre biomarcadores y probabilidad de eventos cardiovasculares.
- Análisis exploratorio de datasets clínicos con múltiples variables biomédicas
- Aplicación de algoritmos de machine learning para identificar patrones de riesgo
- Evaluación de la precisión predictiva en contextos simulados de investigación
- Desarrollo de una interfaz demostrativa para visualización de resultados analíticos
- Documentación del proceso metodológico para fines educativos
La Solución
Desarrollo de un prototipo investigativo que aplica técnicas de ciencia de datos al análisis de factores de riesgo cardiovascular. El proyecto implementa un modelo Random Forest para clasificación de riesgo, acompañado de una aplicación web en Streamlit que permite explorar visualmente las relaciones entre variables clínicas y resultados predictivos, sirviendo como recurso educativo para entender aplicaciones de machine learning en contextos biomédicos.
- Procesamiento y análisis exploratorio de datasets clínicos públicos para investigación
- Implementación de algoritmos de clasificación supervisada (Random Forest) con fines demostrativos
- Evaluación de métricas de rendimiento del modelo en contexto educativo
- Desarrollo de aplicación web interactiva para visualización de resultados analíticos
- Documentación completa del pipeline desde los datos hasta las predicciones y evaluaciones
- Análisis de importancia de variables para interpretación de factores de riesgo
Características Clave
Análisis Exploratorio
Notebooks detallados para el análisis de normalidad y evaluación de variables bioquímicas.
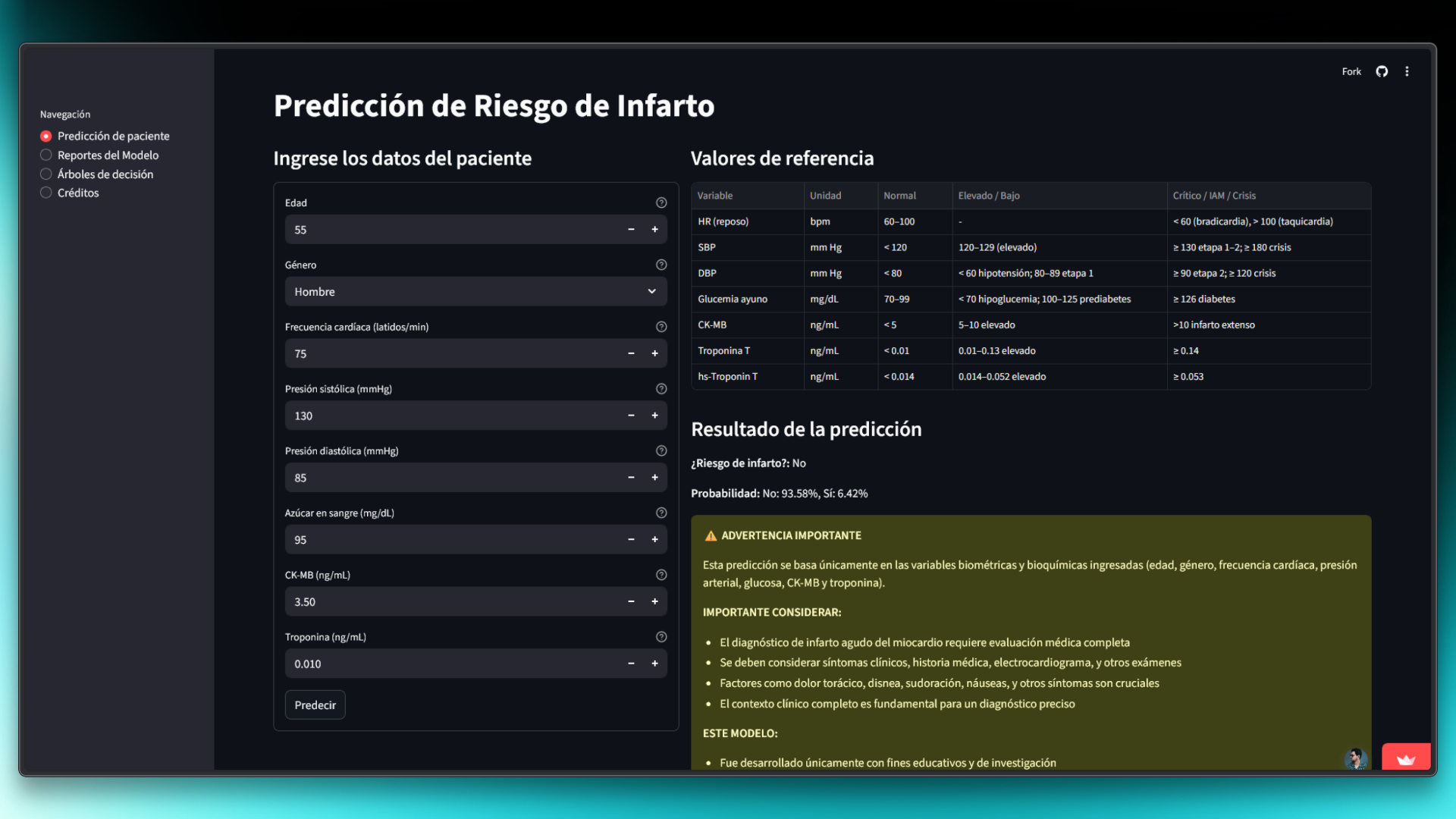
Modelo Predictivo Avanzado
Random Forest optimizado con 150 árboles y profundidad 10, entrenado para predecir ataques cardíacos con alta precisión.
Reportes Automáticos
Generación de informes con métricas de evaluación (Classification Report, ROC, importancia de variables).
Automatización
Pipeline completo de preprocesamiento, entrenamiento y evaluación automatizado con Make.
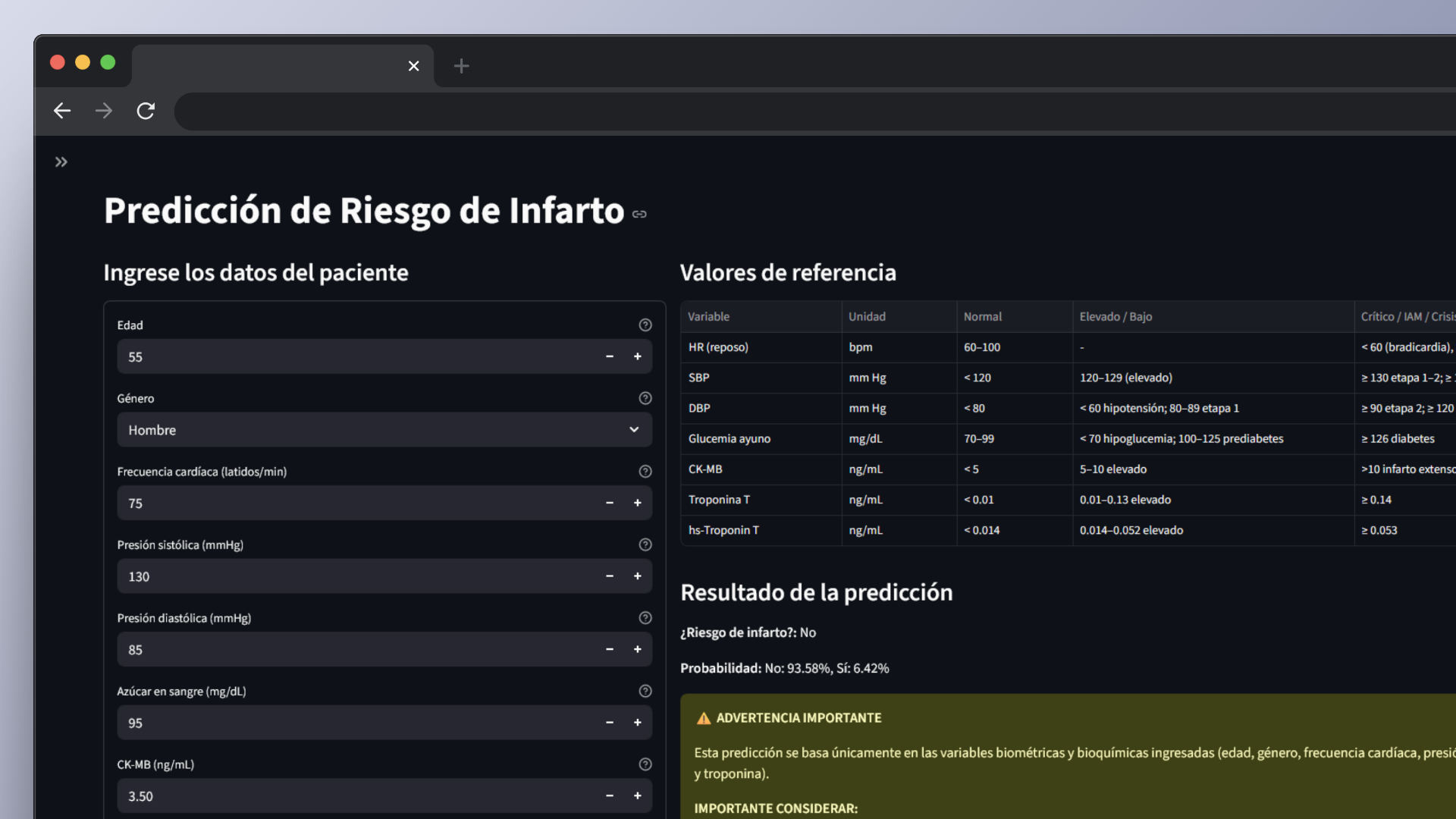
Aplicación Web Interactiva
Interfaz intuitiva en Streamlit para realizar predicciones y visualizar resultados de forma interactiva.
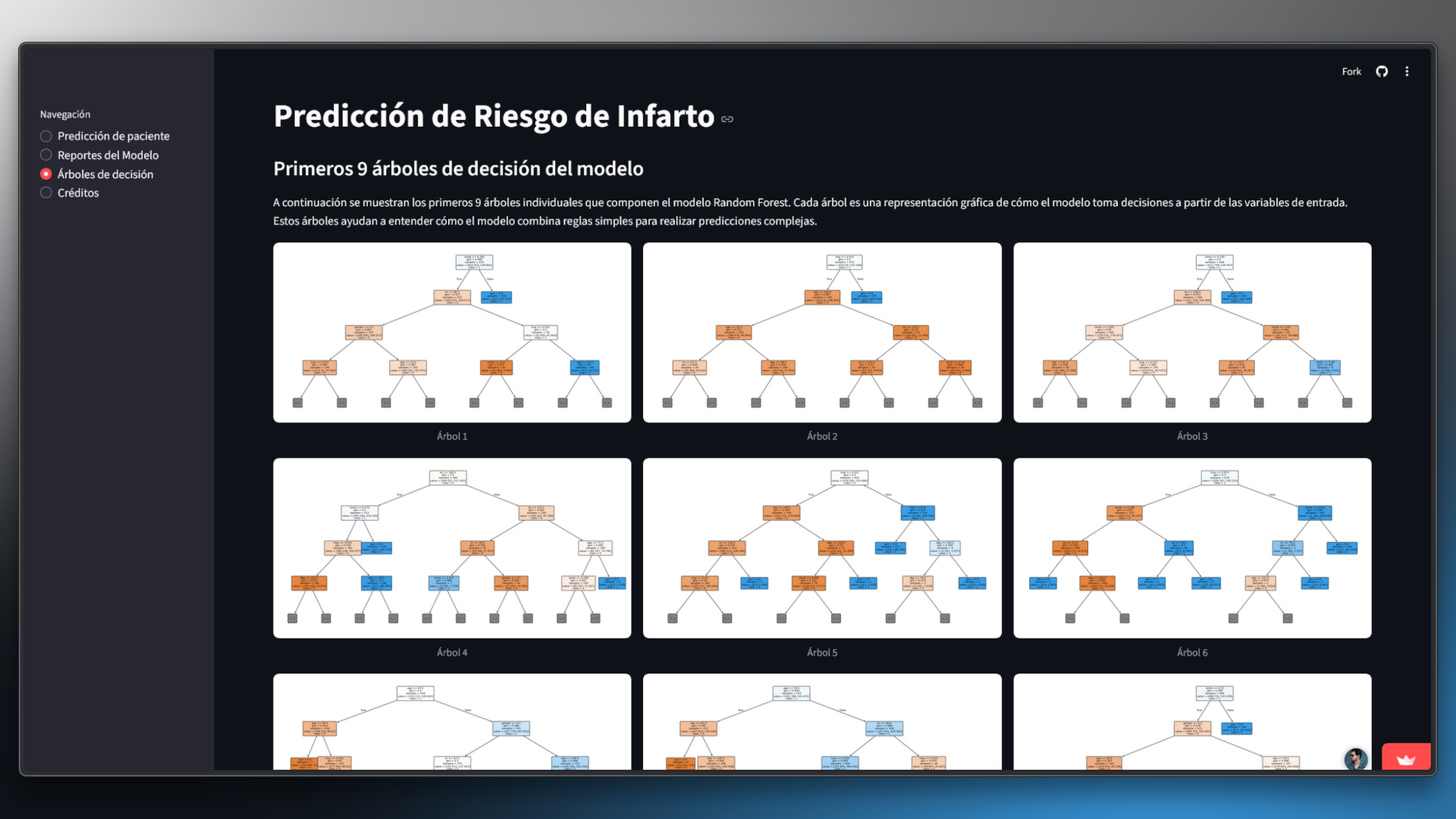
Visualización de Árboles
Herramientas para visualizar los árboles de decisión del modelo y entender las predicciones.
Tecnologías
Información del Proyecto
- Tipo
- Proyecto de Ciencia de Datos
- Año
- 2025
- Equipo
- Proyecto de Postgrado
- Duración
- 1 mes
Capturas de Pantalla