Overview
Data science project to predict heart attacks through exploratory and multivariate analysis of clinical data. Developed as a final project for the postgraduate degree in Data Science applied to Medicine and Biology at the University of Barcelona.
The Problem
Early prediction of cardiovascular risk represents a complex analytical challenge that requires identifying subtle patterns in multiple clinical variables. This project aims to demonstrate how data science techniques can be applied to the analysis of cardiovascular risk factors, providing an educational tool to better understand relationships between biomarkers and cardiovascular event probability.
- Exploratory analysis of clinical datasets with multiple biomedical variables
- Application of machine learning algorithms to identify risk patterns
- Evaluation of predictive accuracy in simulated research contexts
- Development of a demonstrative interface for visualizing analytical results
- Documentation of the methodological process for educational purposes
The Solution
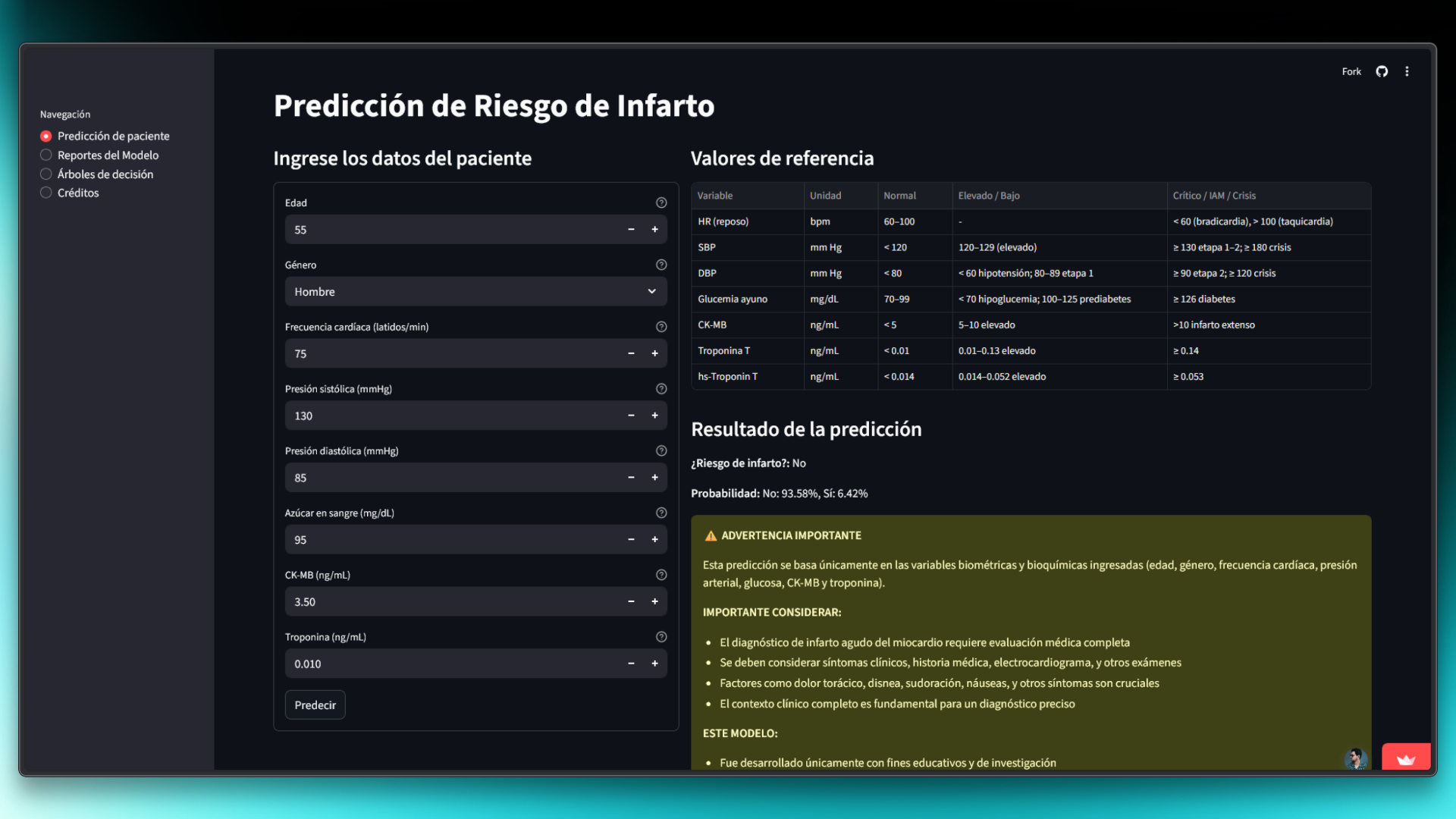
Development of an investigative prototype that applies data science techniques to the analysis of cardiovascular risk factors. The project implements a Random Forest model for risk classification, accompanied by an interactive Streamlit web application that allows visual exploration of relationships between clinical variables and predictive outcomes, serving as an educational resource for understanding machine learning applications in biomedical contexts.
- Processing and exploratory analysis of public clinical datasets for research
- Implementation of supervised classification algorithms (Random Forest) for demonstration purposes
- Evaluation of model performance metrics in an educational context
- Development of an interactive web interface for visualizing analytical results
- Complete documentation of the pipeline from data to predictions and evaluations
- Analysis of variable importance for interpretation of risk factors
Key Features
Exploratory Analysis
Detailed notebooks for normality analysis and evaluation of biochemical variables.
Advanced Predictive Model
Random Forest optimized with 150 trees and depth 10, trained to predict heart attacks with high accuracy.
Automatic Reports
Generation of reports with evaluation metrics (Classification Report, ROC, variable importance).
Automation
Complete pipeline of preprocessing, training and evaluation automated with Make.
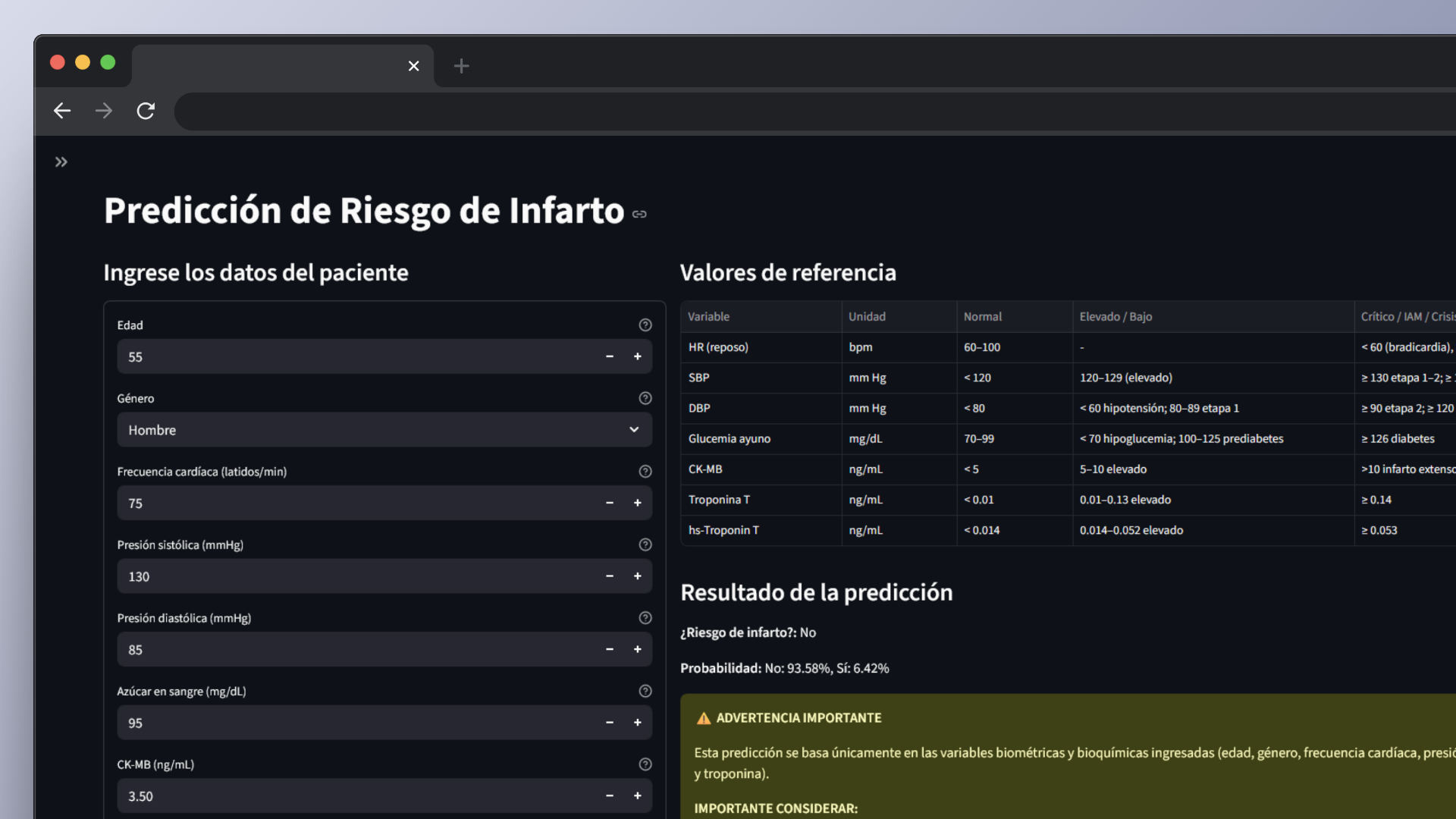
Interactive Web Application
Intuitive interface in Streamlit to make predictions and visualize results interactively.
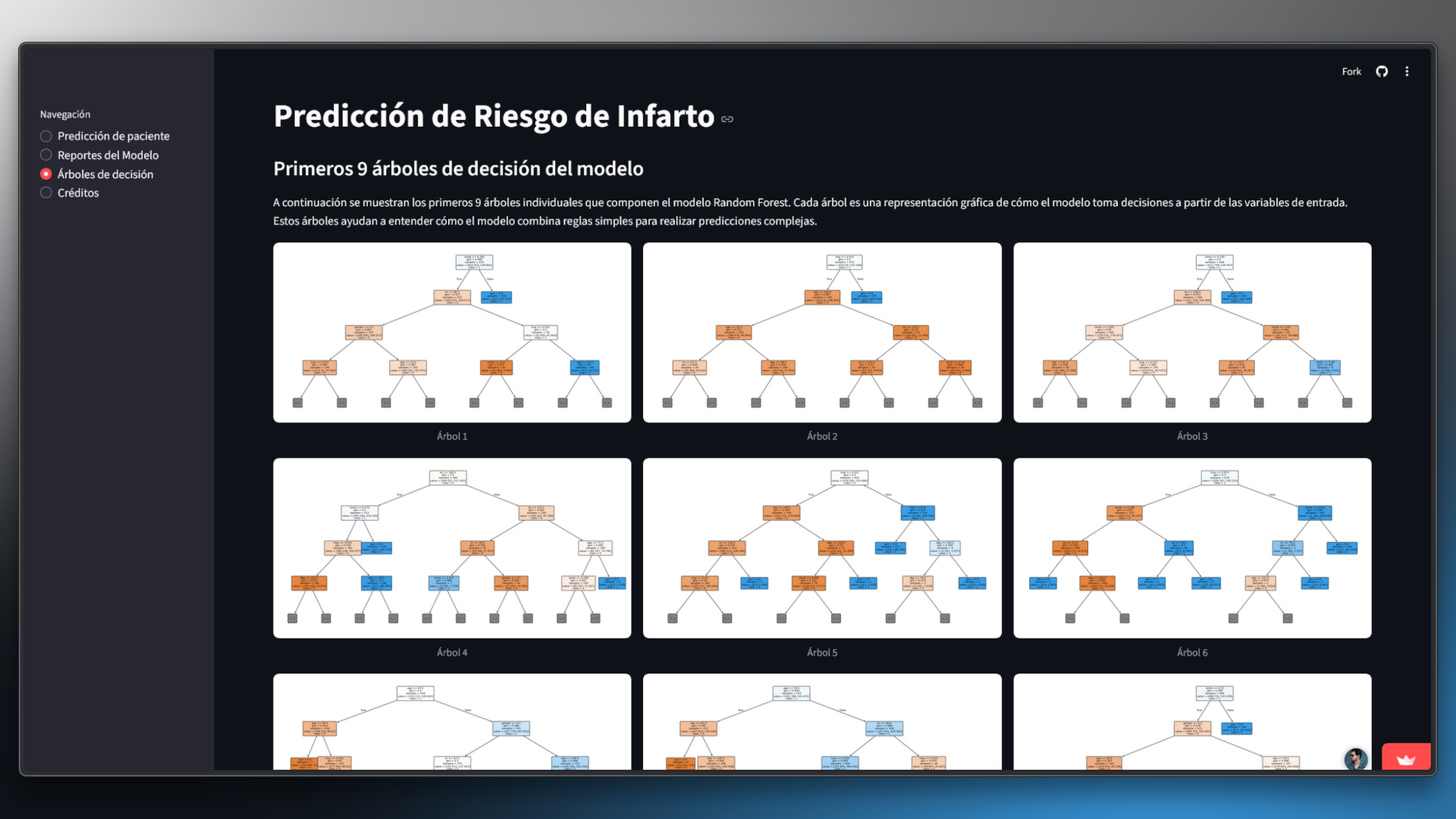
Tree Visualization
Tools to visualize the decision trees of the model and understand the predictions.
Tech Stack
Project Info
- Type
- Data Science Project
- Year
- 2025
- Team
- Postgraduate Project
- Duration
- 1 month
Screenshots